First Unique Character In A String
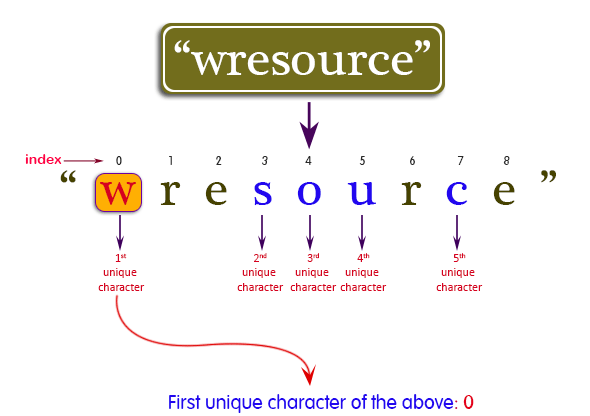
First Unique Character In A String
The "First Unique Character in a String" problem is a common programming problem that often appears in coding interviews. The goal is to find the first non-repeating character in a given string and return its index.
Approach
One common approach to solving this problem involves using a hash map to store the frequency of each character in the string. The algorithm typically involves two passes through the string:
- First Pass:
- Create a hash map to store the frequency of each character.
- Iterate through the string, updating the frequency in the hash map.
- Second Pass:
- Iterate through the string again.
- Check the frequency of each character in the hash map.
- Return the index of the first character with a frequency of 1.
Code(Python)
def firstUniqueChar(s):
# First pass to count character frequencies
char_count = {}
for char in s:
char_count[char] = char_count.get(char, 0) + 1
# Second pass to find the first unique character
for i, char in enumerate(s):
if char_count[char] == 1:
return i
# If no unique character is found
return -1
# Example usage
input_string = input()
result = firstUniqueChar(input_string)
print(result)
# Input: strings
# Output: 1
Step-by-step Explanation of python code
-
Function Definition:
def firstUniqueChar(s):defines a function namedfirstUniqueCharthat takes a stringsas input.
-
Initialize Dictionary:
char_count = {}initializes an empty dictionarychar_countthat will be used to store the frequency of each character.
-
First Pass: Counting Frequencies:
for char in s:iterates through each character in the input strings.char_count[char] = char_count.get(char, 0) + 1updates the frequency count for the current character. If the character is not in the dictionary, it sets the count to 1; otherwise, it increments the existing count by 1.
Second Pass: Finding the First Unique Character:
for i, char in enumerate(s):iterates through each character in the input string along with its index using theenumeratefunction.if char_count[char] == 1:checks if the current character has a frequency of 1 in thechar_countdictionary.return ireturns the index of the first unique character.
Default Return:
- If no unique character is found in the second pass, the function returns
1to indicate that there is no unique character in the string.
Code(Java)
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
public class FirstUniqueCharacter {
public static int firstUniqueChar(String s) {
// First pass to count character frequencies
Map<Character, Integer> charCount = new HashMap<>();
for (char c : s.toCharArray()) {
charCount.put(c, charCount.getOrDefault(c, 0) + 1);
}
// Second pass to find the first unique character
for (int i = 0; i < s.length(); i++) {
if (charCount.get(s.charAt(i)) == 1) {
return i;
}
}
// If no unique character is found
return -1;
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String inputString = scanner.nextLine();
int result = firstUniqueChar(inputString);
System.out.println(result);
scanner.close();
}
}
//input: example
//output : 1
Step-by-step explanation for java code
-
Import Statements:
import java.util.HashMap;andimport java.util.Map;import the necessary classes for using a HashMap.
-
Class Definition:
public class FirstUniqueCharacter {defines a class namedFirstUniqueCharacter.
-
Method Definition:
public static int firstUniqueChar(String s) {defines a static method namedfirstUniqueCharthat takes a stringsas a parameter and returns an integer.
-
Initialize HashMap:
Map<Character, Integer> charCount = new HashMap<>();creates a HashMap calledcharCountto store the frequency of each character.
-
First Pass: Counting Frequencies:
for (char c : s.toCharArray()) {iterates through each character in the stringsby converting it to a char array.charCount.put(c, charCount.getOrDefault(c, 0) + 1);updates the frequency count for the current character. If the character is not in the map, it sets the count to 1; otherwise, it increments the existing count by 1.
Second Pass: Finding the First Unique Character:
for (int i = 0; i < s.length(); i++) {iterates through each index of the string.if (charCount.get(s.charAt(i)) == 1) {checks if the current character has a frequency of 1 in thecharCountmap.return i;returns the index of the first unique character.
Default Return and Main Method:
return -1;is reached if no unique character is found during the second pass.public static void main(String[] args) {defines themainmethod where an example string "leetcode" is used as input to thefirstUniqueCharmethod, and the result is printed to the console.
This Java code essentially follows the same logic as the Python code, using a HashMap to count character frequencies and two passes through the string to find the first unique character. The output will be
0, indicating that the first unique character in the string "example" is at index 1
Code(C++)
#include <iostream>
#include <unordered_map>
int firstUniqueChar(std::string s) {
// First pass to count character frequencies
std::unordered_map<char, int> charCount;
for (char c : s) {
charCount[c]++;
}
// Second pass to find the first unique character
for (int i = 0; i < s.length(); i++) {
if (charCount[s[i]] == 1) {
return i;
}
}
// If no unique character is found
return -1;
}
int main() {
std::string inputString;
std::getline(std::cin, inputString);
int result = firstUniqueChar(inputString);
std::cout << result << std::endl;
return 0;
}
//input : allocate
//output : 3
Step-by-step explanation for c++ code
-
Include Statements:
#include <iostream>and#include <unordered_map>include the necessary libraries for input/output and using an unordered map.
-
Function Definition:
int firstUniqueChar(std::string s) {defines a function namedfirstUniqueCharthat takes a stringsas a parameter and returns an integer.
-
Initialize Unordered Map:
std::unordered_map<char, int> charCount;creates an unordered map calledcharCountto store the frequency of each character.
-
First Pass: Counting Frequencies:
for (char c : s) {iterates through each character in the strings.charCount[c]++;increments the frequency count for the current character.
Second Pass: Finding the First Unique Character:
for (int i = 0; i < s.length(); i++) {iterates through each index of the string.if (charCount[s[i]] == 1) {checks if the frequency of the character at the current index is 1 in thecharCountmap.return i;returns the index of the first unique character.
Default Return and Main Function:
return -1;is reached if no unique character is found during the second pass.int main() {defines themainfunction where an example string "leetcode" is used as input to thefirstUniqueCharfunction, and the result is printed to the console usingstd::cout.
This C++ code follows the same logic as the Python and Java codes, using an unordered map to count character frequencies and two passes through the string to find the first unique character. The output will be
0, indicating that the first unique character in the string "example" is at index 1.
Real World Applications
1. Text Analytics and Natural Language Processing (NLP):
- In NLP applications, analyzing the frequency of characters in a text can provide valuable insights into the language structure. Identifying the first unique character might be useful for tasks such as text summarization, sentiment analysis, and language translation.
2. Spell Checking and Auto-correction:
- Spell checkers often need to identify and correct misspelled words. Finding the first unique character can be a step in detecting errors and suggesting corrections in a given word.
3. Data Cleaning in Databases:
- When dealing with large datasets, it's common to encounter errors or inconsistencies. Finding the first unique character in a string can help identify anomalies or errors in data, facilitating data cleaning processes.
4. Cryptanalysis:
- In the field of cryptography, analyzing patterns in encrypted text might involve finding unique characters. This can be relevant in breaking certain types of ciphers or codes.
5. Programming and Compiler Design:
- Compilers and interpreters often need to analyze source code. Detecting the first unique character in a string could be part of lexical analysis, where the source code is broken down into tokens for further processing.
6. Network Security:
- In cybersecurity, analyzing network traffic or logs may involve identifying unique patterns or signatures. The first unique character in a string could be a part of this process, helping to detect and analyze potential security threats.
7. DNA Sequence Analysis:
- In bioinformatics, the problem of finding the first unique character can be analogous to identifying unique sequences in DNA. This is crucial for tasks like gene mapping and understanding genetic variations.
8. Image Processing:
- In certain image processing applications, text recognition involves analyzing characters in an image. Identifying the first unique character can be a step in recognizing and extracting text from images.
9. Data Compression:
- In data compression algorithms, identifying patterns and unique characters in a stream of data is fundamental. This helps in designing efficient compression techniques.
Test Cases
-
Input: allocate Output: 3 The Function returns the index of the first unique character in the string. It does this by first counting the frequencies of each character in the string and then iterating through the string again to find the first character with a count of 1. For the input "allocate":
Character counts:
'a': 2 'l': 2 'o': 1 'c': 1 't': 1 'e': 1
In the example usage: 'a' and 'l' occur more than once, so they are not unique. 'o' at index 3 is the first character with a count of 1, making it the first unique character, so the function returns 3. Hence, the output for the input "allocate" is 3.
-
Input: example Output: 1
For the input "example":
Character counts: 'e': 2 'x': 1 'a': 1 'm': 1 'p': 1 'l': 1
In the example usage: 'e' occurs more than once, so it's not unique. 'x', 'a', 'm', 'p', and 'l' all occur only once, making them unique characters. The first unique character is 'x' at index 1, so the function returns 1. Hence, the output for the input "example" is 1.